Matrix Multiplication
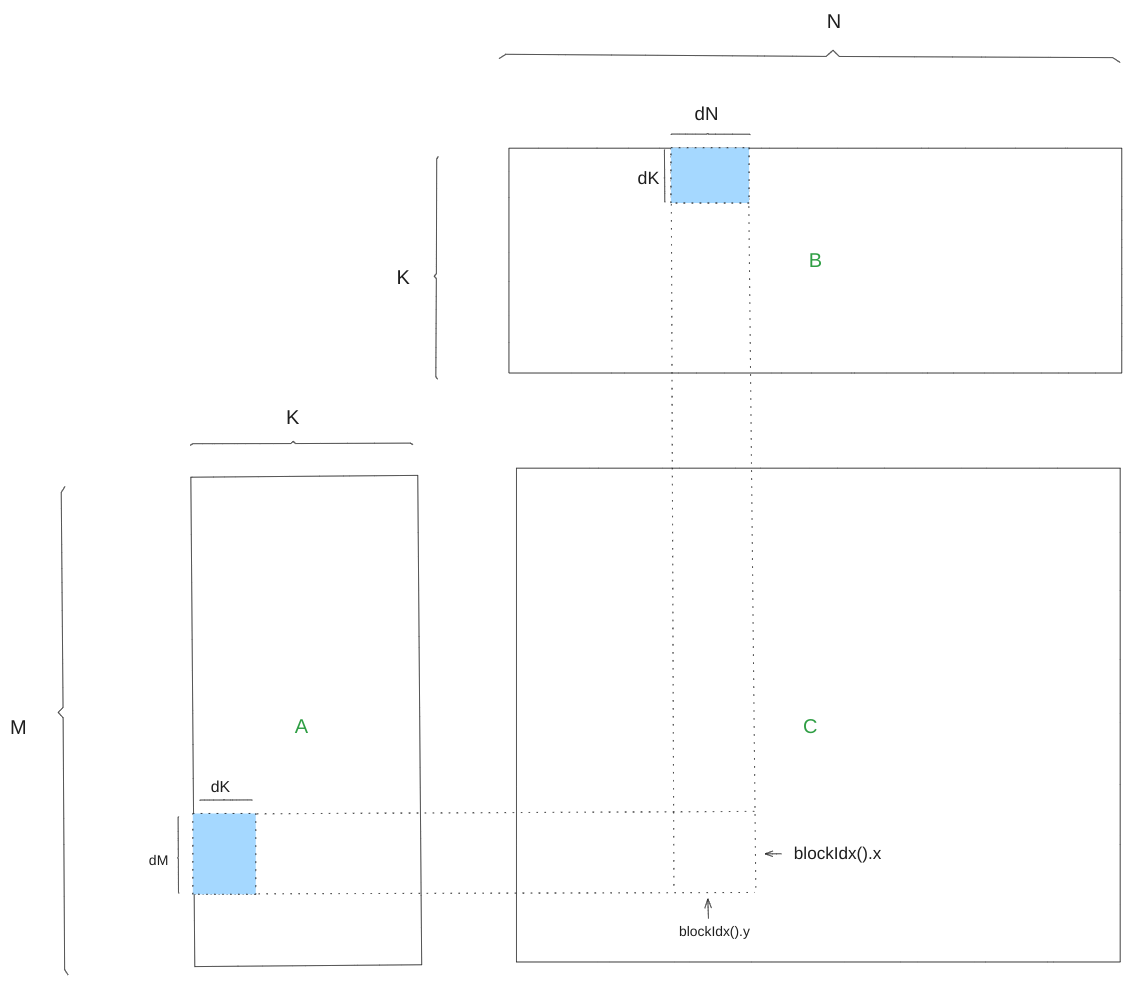
This tutorial explores matrix multiplication using MoYe.jl, specifically computing the product $C = A \times B^T$. Here, A is an $(M, K)$ matrix, B is a $(N, K)$ matrix, and C is an $(M, N)$ matrix.
Tiling Strategy
We divide the computation among thread blocks, where each block computes a tile of C of size (bM, bN). The tile index is determined by (blockIdx().x, blockIdx().y).
Computing a tile of C requires a corresponding tile of A of shape (bM, K) and a tile of B of shape (bN, K). To minimize global memory access, we further partition A and B along the K dimension into smaller tiles of size (bM, bK) and (bN, bK), respectively. These smaller tiles are loaded into shared memory sequentially.
Global Memory Partitioning
The global memory partitioning is defined as follows:
gC = @tile C (bM, bN) (blockIdx().x, blockIdx().y) # (bM, bN)
gA = @tile A (bM, bK) (blockIdx().x, :) # (bM, bK, K/bK)
gB = @tile B (bN, bK) (blockIdx().y, :) # (bN, bK, K/bK)Refer to @tile for more details on the syntax. Here, gA represents a tile of A in global memory. We then loop over the last dimension of gA and gB (denoted as k) to load them into shared memory.
Shared Memory Allocation
Shared memory is allocated using MoYeSharedArray:
sA = MoYeSharedArray(eltype(gA), sA_layout) # (bM, bK)
sB = MoYeSharedArray(eltype(gB), sB_layout) # (bN, bK)MoYeSharedArray automatically allocates shared memory of size cosize(sA_layout) + cosize(sB_layout) and returns a MoYeArray. The layouts sA_layout and sB_layout are predefined at compile time.
Thread Partitioning
We then define how thread groups copy data from global to shared memory. For example:
tA = @Layout (32, 8)
tB = @Layout (32, 8)This creates a 32x8 thread group in column-major format. We use this to partition the arrays:
tAgA = @parallelize gA tA threadIdx().x # (THR_M, THR_K, k)
tBgB = @parallelize gB tB threadIdx().x # (THR_M, THR_K, k)
tAsA = @parallelize sA tA threadIdx().x # (THR_N, THR_K)
tBsB = @parallelize sB tB threadIdx().x # (THR_N, THR_K)Refer to @parallelize for more details. After partitioning, copying is straightforward:
copyto!(tAsA, view(tAgA, :, :, k))
copyto!(tBsB, view(tBgB, :, :, k))MMA Computation
For the matrix-multiply-accumulate (MMA) computation, we define another thread group layout:
tC = @Layout (16, 16)We then partition gC:
tCgC = @parallelize gC tC threadIdx().x # (THR_M, THR_N)
tCrC = similar(tCgC)To reduce memory access to C, we create tCrC in registers to serve as an accumulator. The results are copied back to tCgC after the computation.
Computing an element in C requires a full row from A and a full column from B:
tCsA = @parallelize sA tC threadIdx().x (1, :) # (THR_M, bK)
tCsB = @parallelize sB tC threadIdx().x (:, 1) # (THR_N, bK)Finally, the matrix multiplication can be performed:
for k in axes(tCsA, 2)
for m in axes(tCsA, 1)
for n in axes(tCsB, 1)
@inbounds tCrC[m, n] += tCsA[m, k] * tCsB[n, k]
end
end
endAlternatively, you can use the gemm! function:
gemm!(tCrC, tCsA, tCsB, tCrC)Complete Kernel
function matmul_kernel(A, sA_layout, tA,
B, sB_layout, tB,
C, tC)
sA = MoYeSharedArray(eltype(A), sA_layout) # (bM, bK)
sB = MoYeSharedArray(eltype(B), sB_layout) # (bN, bK)
mA = MoYeArray(A)
mB = MoYeArray(B)
mC = MoYeArray(C)
bM = size(sA_layout, 1)
bN = size(sB_layout, 1)
bK = size(sB_layout, 2)
gA = @tile mA (bM, bK) (blockIdx().x, :) # (bM, bK, K/bK)
gB = @tile mB (bN, bK) (blockIdx().y, :) # (bN, bK, K/bK)
gC = @tile mC (bM, bN) (blockIdx().x, blockIdx().y) # (bM, bN)
# Copy partition
tAgA = @parallelize gA tA threadIdx().x # (THR_M, THR_K, k)
tBgB = @parallelize gB tB threadIdx().x # (THR_M, THR_K, k)
tAsA = @parallelize sA tA threadIdx().x # (THR_N, THR_K)
tBsB = @parallelize sB tB threadIdx().x # (THR_N, THR_K)
# MMA partition
tCsA = @parallelize sA tC threadIdx().x (1, :) # (THR_M, bK)
tCsB = @parallelize sB tC threadIdx().x (:, 1) # (THR_N, bK)
tCgC = @parallelize gC tC threadIdx().x # (THR_M, THR_N)
# Accumulator
tCrC = similar(tCgC) # (THR_M, THR_N)
zeros!(tCrC)
for k in axes(tAgA, 3)
copyto!(tAsA, view(tAgA, :, :, k))
copyto!(tBsB, view(tBgB, :, :, k))
cp_async_wait()
sync_threads()
@gc_preserve gemm!(tCrC, tCsA, tCsB, tCrC)
sync_threads()
end
copyto!(tCgC, tCrC)
return nothing
endDesign Considerations
Shared Memory Layout
To avoid bank conflicts in shared memory, we pad the layouts by one column:
sA_layout = make_layout((bM, bK), (_1, bM + _1))
sB_layout = make_layout((bN, bK), (_1, bN + _1))Thread Layout for MMA
The shape of tC must evenly divide (bM, bN).
Thread Layout for Copying
To achieve memory coalescing, every 32 threads should access contiguous elements in A and B. The optimal design depends on the memory layout of A and B.
Host Function
function matmul(A, B, C)
bM = _128
bN = _128
bK = _8
sA_layout = make_layout((bM, bK), (_1, bM + _1))
sB_layout = make_layout((bN, bK), (_1, bN + _1))
tA = @Layout (32, 8)
tB = @Layout (32, 8)
tC = @Layout (16, 16)
threads = Int(size(tC))
blocks = (cld(size(A, 1), bM), cld(size(B, 1), bN))
@cuda threads=threads blocks=blocks matmul_kernel(A, sA_layout, tA,
B, sB_layout, tB,
C, tC)
end
function test()
A = CUDA.randn(Float32, 2048, 256)
B = CUDA.randn(Float32, 2048, 256)
C = CUDA.randn(Float32, 2048, 2048)
matmul(A, B, C)
CUDA.synchronize()
@test C == A * B'
CUDA.unsafe_free!(A)
CUDA.unsafe_free!(B)
CUDA.unsafe_free!(C)
end
test()This concludes the guide to implementing matrix multiplication with MoYe.jl, focusing on efficient memory management and tiling strategies.